
Il y a eu dans le passé de nombreuses tentatives d’implémentation d’un système global de fichiers distribués. Certains d’entre eux ont eu un succès significatif. Si parmi les tentatives académiques on peut citer AFS, c’est en dehors du milieu universitaire qu’on trouve les systèmes les plus performants. Les applications peer-to-peer de partage de fichiers principalement orientés audio et vidéo Napster, KaZaA et BitTorrent supportent plus de 100 millions d’utilisateurs simultanés. BitTorrent gère des dizaines de millions de nœuds quotidiennement.
Bien que ces infrastructures servent un très grand nombre d’utilisateurs, elles ne sont pas conçues pour y construire des applications et leur seule fonctionnalité reste l’échange de fichiers. Si on n’a jamais essayé d’aller plus loin c’est peut-être parce qu’une solution assez bonne, couvrant la plupart des cas d’utilisation, existe déjà: le HTTP. De loin, HTTP est le système distribué de fichiers le plus réussi jamais déployé. Couplé avec les navigateurs, il a eu un énorme impact technique et social.
Pourtant il vieillit (n’évoluant pas ou très peu) et il ne peut pas tirer profit d’une bonne dizaines de brillantes techniques de distribution inventées au cours des quinze dernières années. Le moment est-il venu de changer la colonne vertébrale du web? Peut-on envisager de déplacer l’HTTP ?
L’industrie aime l’HTTP car le déplacement de petits fichiers est relativement bon marché, même pour les petits sites ayant beaucoup de trafic. Mais nous entrons dans une nouvelle ère et la distribution de données nous impose de nouveaux défis:
- l’hébergement et la distribution de bases de données de la taille du pétaoctet,
- l’informatique big-data et le croisement de gros volumes de données entre organisations,
- le streaming à la demande en haute définition, à haut volume et en temps réel,
- le versioning et le linking des bases de données massives,
- la prévention de la disparition accidentelle de fichiers importants,
- …
Tous ces défis peuvent se résumer en une seule phrase: gros volumes de données, accessibles partout dans le monde.
Hélas, les préoccupations sur la bande passante, combinées à certaines de ses caractéristiques critiques nous ont déjà fait renoncer à l’HTTP comme point de départ pour construire des protocoles de distribution qui répondraient à ces défis.
Parallèlement, les systèmes de contrôle de version savent gérer d’importants flux de travail de collaboration de données. Git par exemple offre des fonctionnalités de versioning polyvalentes qui font défaut aux grands systèmes de distribution de fichiers. Il serait pourtant très intéressant d’unir ces deux mondes. De nouvelles solutions inspirées par Git émergent déjà, tels que Camlistore, un système personnel de stockage de fichiers et Dat, un gestionnaire collaboratif de partage et package de données.
Git peut-il influencer la conception des systèmes de fichiers distribués orientés haut débit? Si oui, comment pourrait-il améliorer le Web lui-même?
***
IPFS est le nouveau système de partage des fichiers distribués en peer-to-peer sous contrôle de version. IPFS intègre et synthétise de nombreuses technologies qui ont fait leurs preuves par le passé, donnant un système plus grand que la somme de ses parties, tout comme le bitcoin. Mis à part Bitswap, qui est un protocole tout nouveau, la principale contribution de IPFS est le couplage des systèmes existants et la synthèse des modèles externes.
- La technologie Distributed Hash Tables (DHT):
– Kademlia DHT,
– Coral DSHT,
– S / Kademlia DHT - Bloquer les échanges – BitTorrent
- Systèmes de contrôle de version Git –
- Auto-certifié Filesystems – SFS
***
IPFS est une nouvelle plateforme pour y écrire et déployer des applications, ainsi qu’un nouveau système pour distribuer et versionner de gros volumes de données. Le principe central de IPFS est de modéliser toutes les données dans le cadre du même Merkle DAG. IPFS est peer-to-peer: aucun de ses nœuds n’est privilégié. Les noeuds IPFS stockent localement des objets IPFS et se connectent les uns aux autres en se transférant des objets.
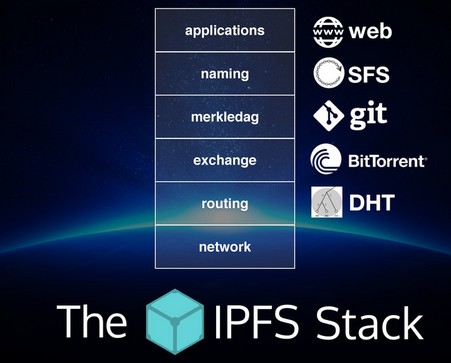
Le Protocole IPFS est divisé en une pile de sous-protocoles responsables de différentes fonctionnalités:
- Identités – gère la génération de l’identité du noeud et sa vérification.
- Réseau – gère les connexions à d’autres pairs, utilise divers protocoles de réseau sous-jacents. Il est configurable.
- Routage – maintient des informations pour localiser des pairs et des objets spécifiques dans le réseau, répond aux requêtes locales et distantes, utilise une DHT par défaut.
- Echange – C’est le seul protocole nouveau: Bitswap. Il régit une distribution efficace des blocs. Modelé comme un market, il incite faiblement la réplication des données.
- Objets – un Merkle DAG d’objets immuables qu’on adresse par contenu, avec des liens. Utilisé pour représenter des structures de données arbitraires et des hiérarchies, par exemple des fichiers et des systèmes de communication.
- Fichiers – un système de fichiers versionnés hiérarchiquement, inspiré par Git.
- Naming – Un système de nom mutable qui s’auto-certifie.
Ces sous-systèmes ne sont pas indépendants, ils sont intégrés et entremêlés dans le protocole. Ils exploitent ainsi l’effet combiné de leurs propriétés mélangées.
***
IPFS est une vision ambitieuse pour une nouvelle infrastructure Internet décentralisée sur laquelle de nombreux types d’applications peuvent être construits.
Au minimum, il peut être utilisé comme un système de fichiers versionné global (qu’on monte localement comme un disque) ou comme le système de partage de fichiers de nouvelle génération.
Au mieux, il peut pousser le Web vers de nouveaux horizons où l’édition d’informations précieuses n’impose pas d’hébergement à l’éditeur. Tout l’hébergement reposerait sur ceux qui sont intéressés et qui sont aussi les premiers utilisateurs des contenus. Les utilisateurs pourraient faire confiance au contenu qu’ils reçoivent sans pour autant faire confiance aux pairs dont ils reçoivent l’information. Sa structure garantit la sauvegarde sûre et infinie d’importants fichiers, même volumineux.
IPFS peut nous apporter le Web permanent. Pour comprendre pourquoi l’utiliser vous pouvez lire ici.
Pour vous faire une idée de la manière dont il marche, voici aussi la démo de la version alpha.
***
IPFS est un allié naturel de la blockchain. Le stockage de données volumineuses coûte cher dans Ethereum et est impossible dans le bitcoin. La solution actuelle est donc de garder le gros de la data dans un dépôt centralisé, c’est ce que font beaucoup d’applications blockchain pour l’instant. Il va de soi que ce palliatif remet en discussion le côté décentralisé d’une appli blockchain.
C’est pourquoi des solutions comme IPFS, Swarm, MaidSafe sont les bienvenues et la recherche dans ce domaine est très active aujourd’hui.
4 réflexions au sujet de « IPFS et la décentralisation du WEB »